

This blog post is the second part of a series. I recommend reading the first part to fully understand the context of this one. In this post, we'll focus on data cleaning, using the results from the first part as our foundation.
Data Cleaning
Step 1. Remove Columns with Excessive Null Values.
df.head(1)

Step 2. Remove duplicated data
df.drop_duplicates(inplace=True)Step 3. Eliminate Rows with Null Values in Essential Columns
df.dropna(subset = ['cast', 'director', 'genres'], how='any', inplace=True)Let's check if there are still null values
df.isnull().sum()
Step 4. Replace zero values with null values in the budget and revenue column.
df['revenue'] = df['revenue'].replace(0, np.NaN)df.info()
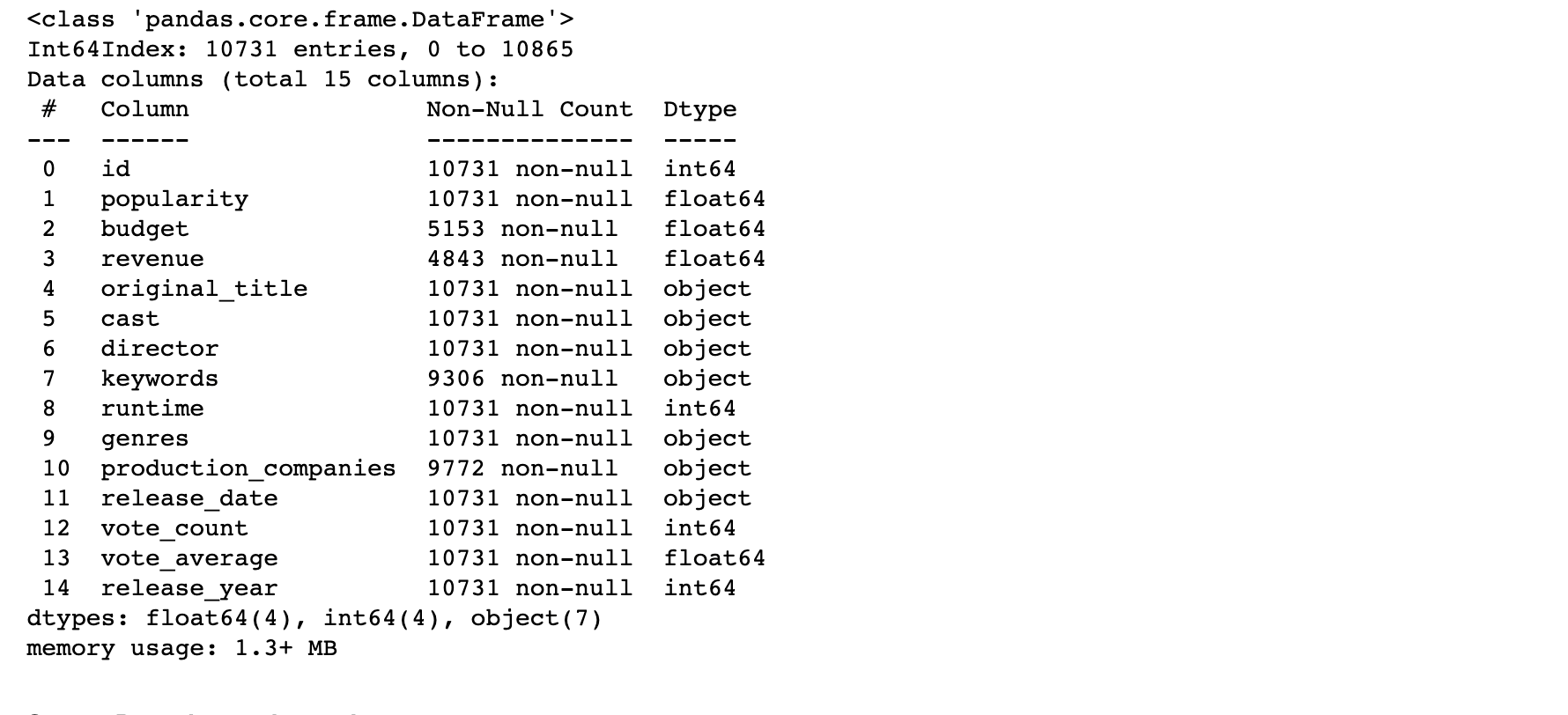
Step 5. Drop the runtime column.
df.query('runtime == 0')

df.info()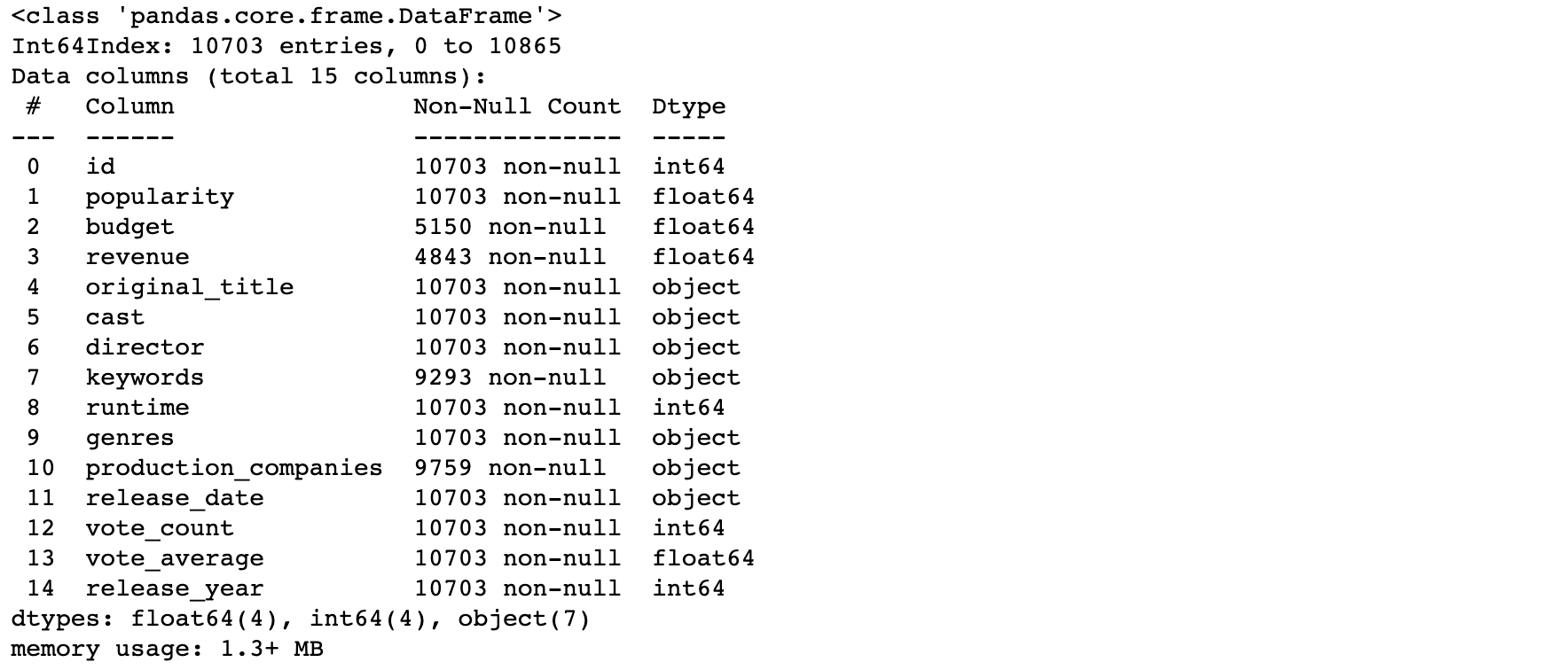
df.describe()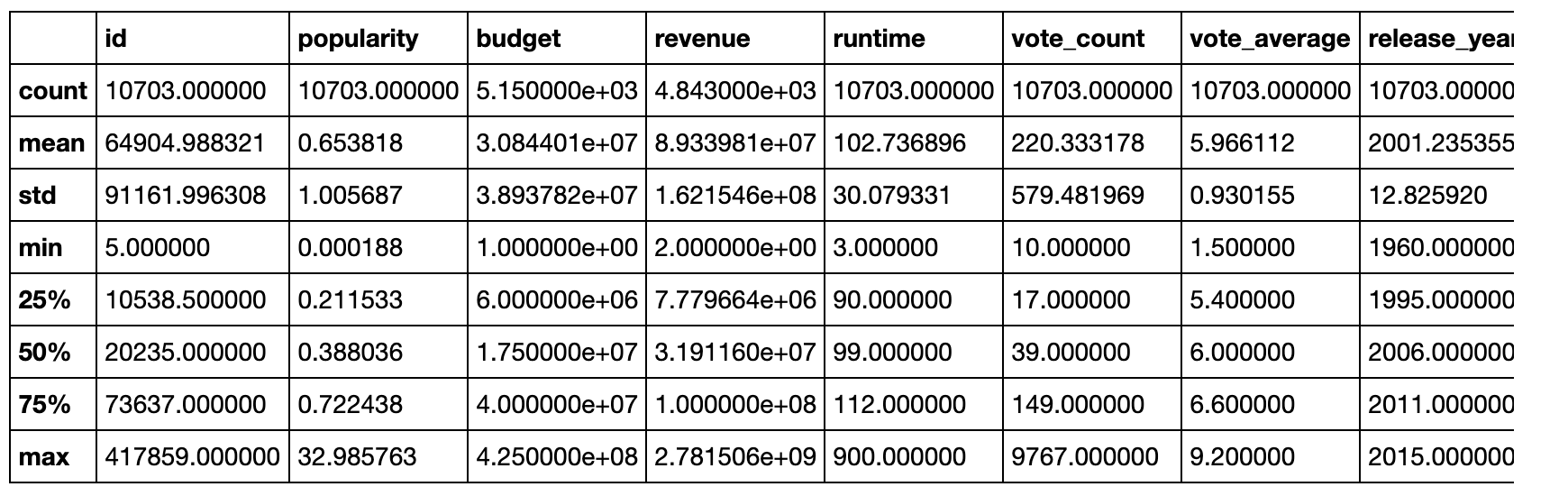
From the table above, we can see that replacing the zeros with null values in the budget and revenue distribution made them look better. We can also see that the minimum makes now more sense
This is the end of the second part. If you got some good time reading, stay tuned. I will post the third part soon.
Thank you for reading.
Discussion