

I participated in the Data analyst nanodegree program from Udacitywhere I worked on a number of projects. In the coming weeks, I will be writing blog posts to share my experiences and insights from these projects.
Note: This blog post is the first part of a series where I analyze a dataset. The goal is to demonstrate how straightforward data analysis can be.Introduction
Are you curious about what makes a movie successful? In this series of blog posts, we'll use data from The Movie Database (TMDb) to explore the factors that contribute to a film's popularity, ratings, and revenue. Our dataset includes information on over 5,000 movies, covering aspects like budget, cast, director, keywords, runtime, genres, production companies, release date, and more.
In this first post, we'll take a closer look at the TMDb movie data and introduce some of the questions we'll be addressing in the coming weeks, such as:
- How has movie popularity changed over the years?
- How does revenue vary across different ratings and popularity levels?
- What characteristics are associated with high-popularity movies?
- How many movies are released each year?
- What are the keyword trends by generation?
Using tools like Numpy, Pandas, and Matplotlib, we'll dive into the data to uncover valuable insights. But before we begin, let's introduce the dataset and discuss its contents.
LET'S GO!!
First, let's import the necessary packages.
import matplotlib.pyplot as plt
import seaborn as sns
from collections import Counter
%matplotlib inline
Data Wrangling
General Properties
Let's load the info of the dataset
df.info()
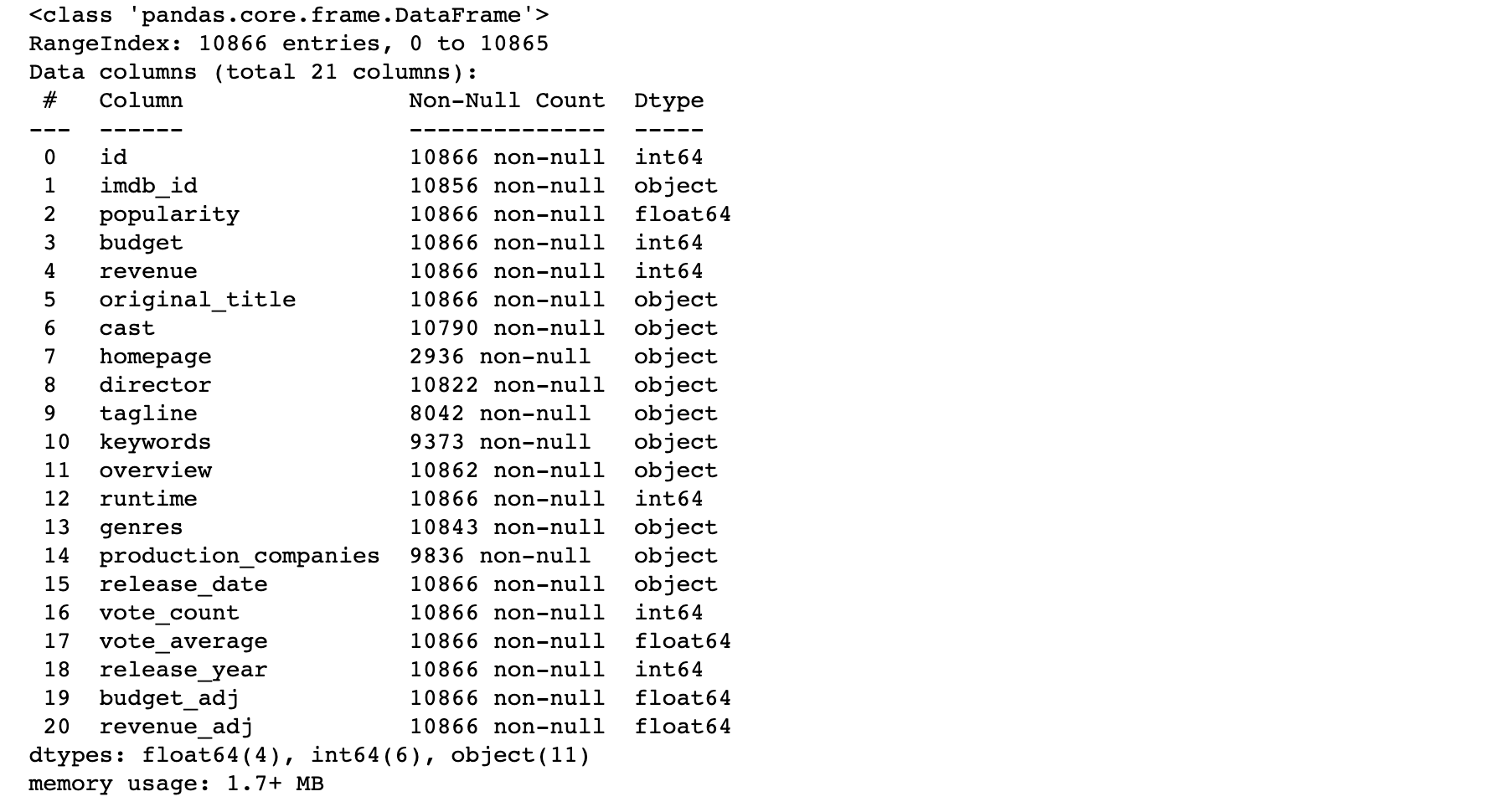
The TMDB movie data includes 10866 entries and 21 columns, with data types including integers, floats, and strings. A significant number of columns have null values, as indicated by the number of entries per column. In the next step, we will examine the exact number of null records per column.
list(df.isnull().sum().items())
After examining the null values in the TMDB movie data, we found that several columns contain null records, including cast, homepage, director, tagline, keywords, overview, genres, and production companies. In particular, the homepage, tagline, keywords, and production_companies columns have a large number of null records. In order to move forward with our analysis, we decided to remove the tagline and keywords columns, which had a high number of null values.
Next, we will try to gather more descriptive information from the dataset.
df.describe()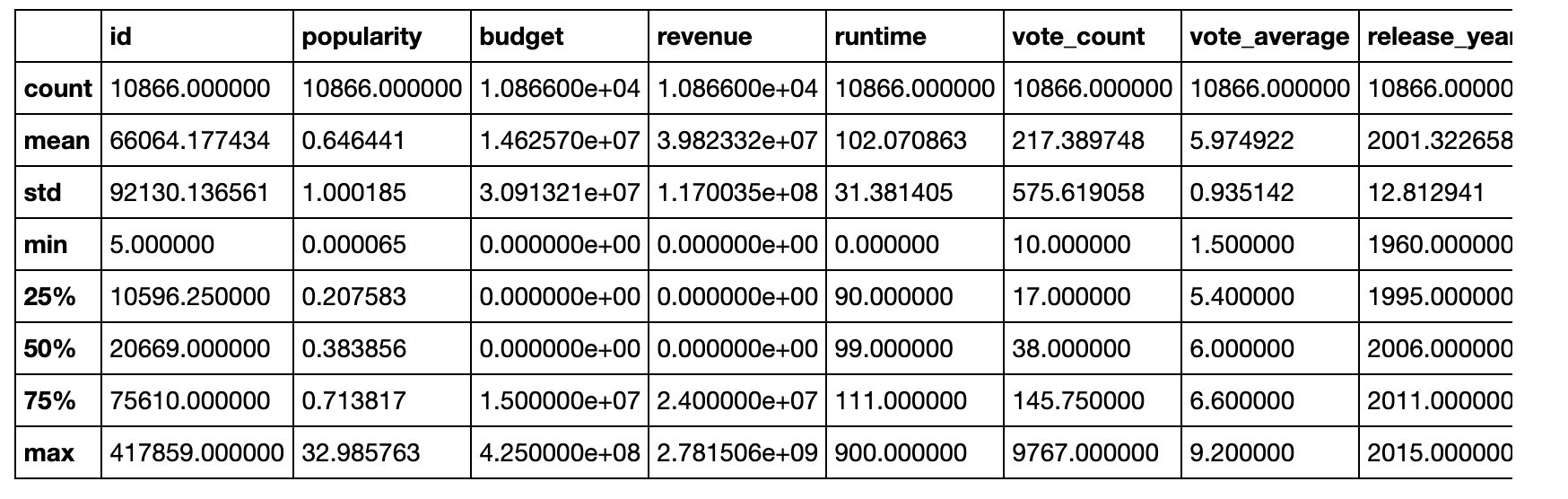
After examining the popularity column in the TMDB movie data, we observed some outliers that appear to be valid data points. Therefore, we decided to retain the original data rather than remove these outliers.
We also noticed that the budget, revenue, and runtime columns contain many zero values. Initially, we considered the possibility that these movies were not released, but upon examining the release_year column, we found that the minimum value (1996) is a valid year and that there were no null values. This suggests that these movies were indeed released, but may have missing data for budget, revenue, and runtime. In order to determine the cause of these zero values, we will closely examine these records and try to gather more information about them.
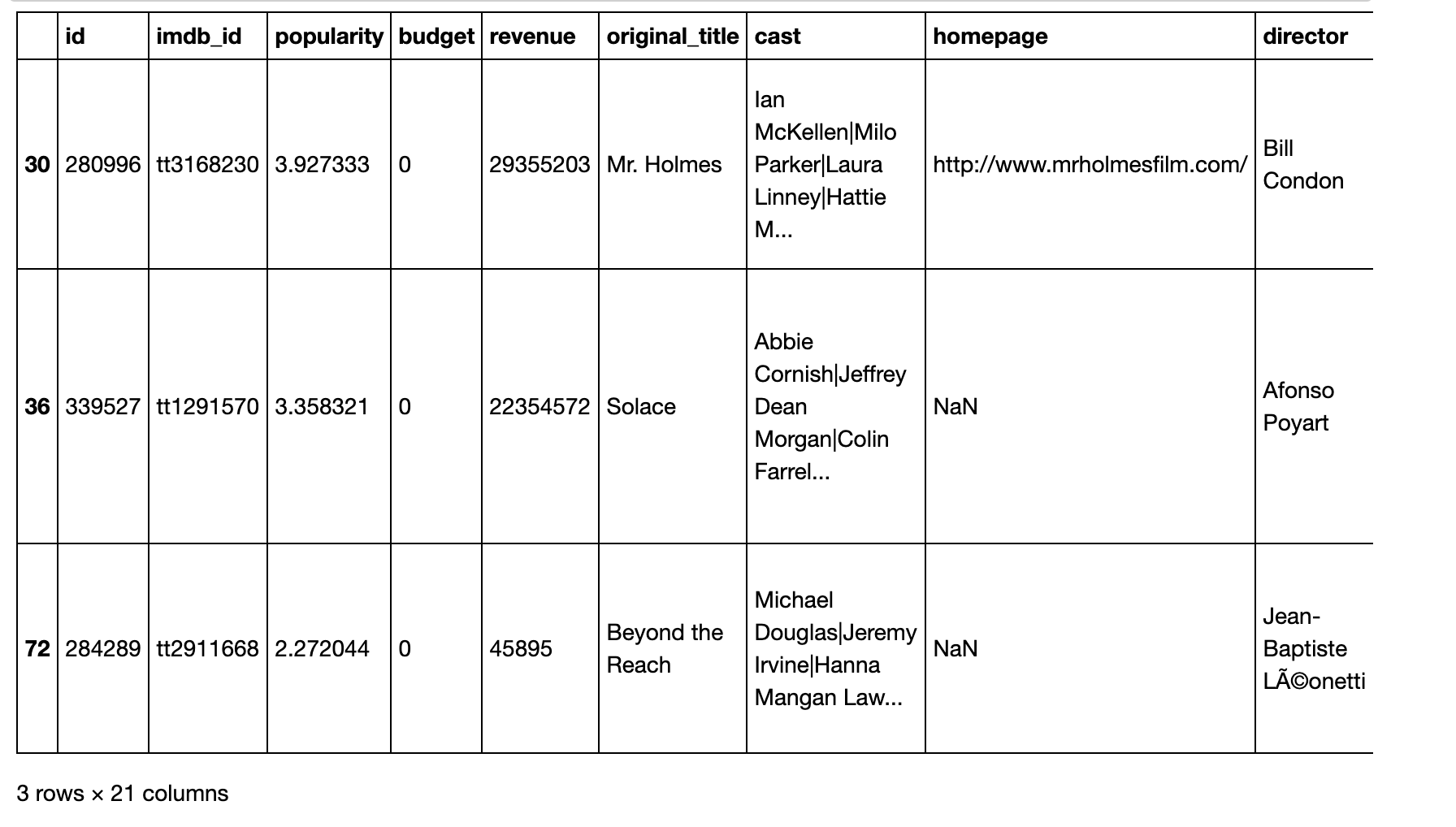
df_budget_zero.head(3)
Then for the revenue
df_revenue_zero.head(3)
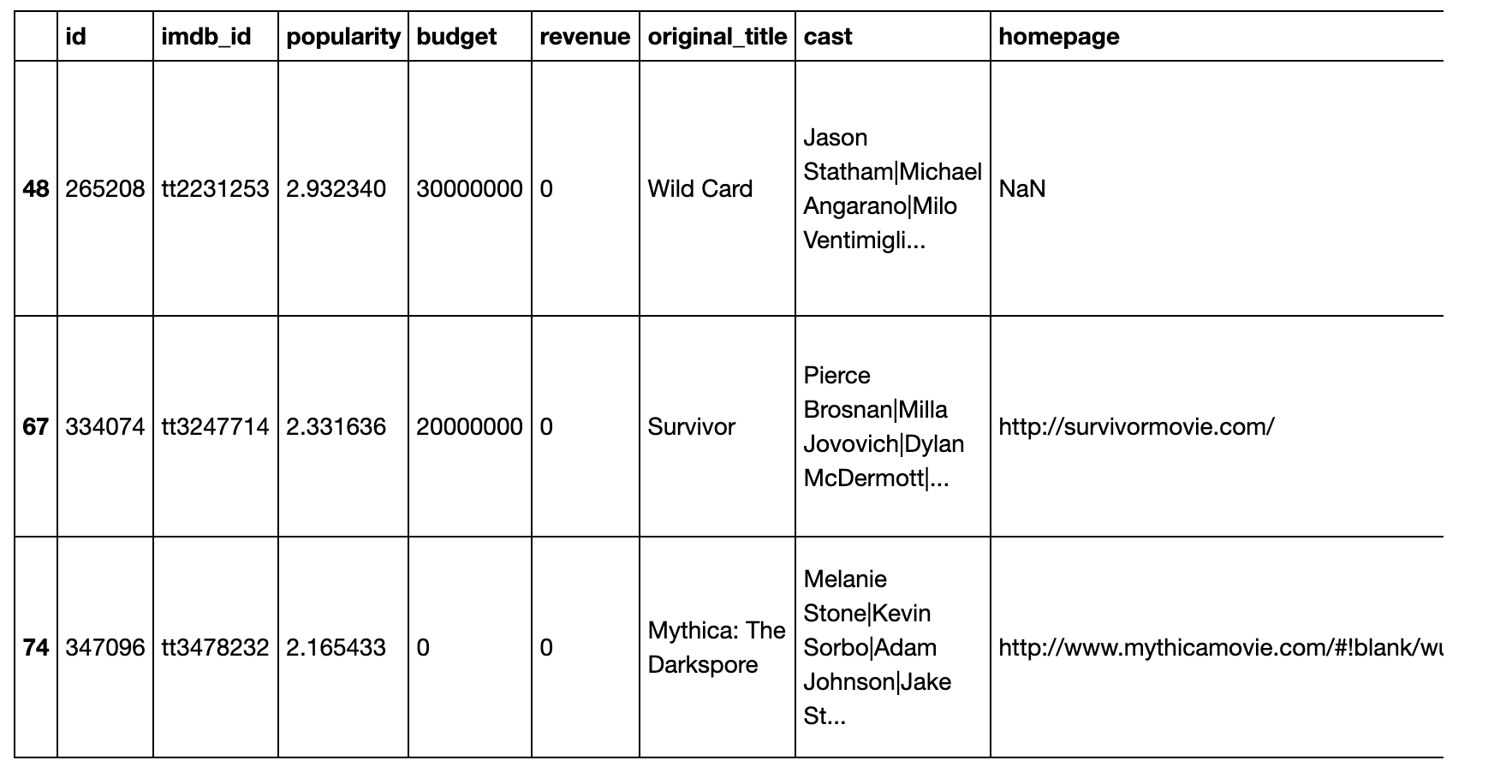
After investigating the records with zero values for budget and revenue, we found that these values were likely missing data rather than indicating that the movies were not released. However, we also discovered that some of these records had other inconsistencies or missing data that could potentially affect the results of our analysis. As a result, we decided to drop these records rather than impute the missing values or set them to zero.
Next, we will check the number of null values in the dataset to determine whether we should drop or impute these values as well.
First for the budget zero values
df_budget_0count.head(2)

As suggested by the results, there are a lot of zero values than non-zero values. Dropping them out would corrupt the results. I better set them as null instead.
Then for the revenue zero values
df_revenue_0count.head(2)

Same situation. Set to null
Finally for the runtime

The number of zeroes is negligible, they can be dropped out
Summary
In this first part of the series, we focused on preparing the TMDB movie data for analysis. We removed some columns that had a lot of null values or were not necessary for answering our research questions, and we also dropped duplicated data. We then removed null values in certain columns and replaced zero values with null values in the budget and revenue columns. Finally, we dropped any rows with a runtime of zero.
Thank you for reading! In the next part of the series, we will continue with data cleaning and begin to explore the data in more depth. Stay tuned!
Ciao 👋🏾
Discussion